
Anthropic vient de franchir une nouvelle étape dans la course à l’intelligence artificielle. Claude Sonnet 4.6, lancé le 17 février 2026, s’impose comme le modèle de milieu de gamme le plus puissant jamais produit par le laboratoire américain. Fenêtre de contexte d’un million de tokens, performances de codage rivalisant avec des modèles de classe supérieure, résistance accrue aux attaques par injection de prompt : ce modèle redéfinit les attentes des développeurs, des chercheurs et des entreprises. Que vous soyez utilisateur de Claude sur l’interface grand public ou développeur intégrant l’API d’Anthropic, voici tout ce qu’il faut savoir sur cette mise à jour majeure.
- Claude Sonnet 4.6 : une mise à jour bien plus qu’incrémentale
- 1 million de tokens en contexte : ce que ça change vraiment
- Des performances de codage qui bousculent la hiérarchie des modèles
- L’utilisation de l’ordinateur : une capacité qui atteint la maturité
- Claude pour les chercheurs : le raisonnement scientifique à grande échelle
- Comment utiliser Claude Sonnet 4.6 : guide pratique
- Via claude.ai (utilisateurs grand public)
- Via l’API (développeurs)
- Nouvelles fonctionnalités API disponibles
- Claude dans l’écosystème : bien plus qu’un simple chatbot
- Sécurité et éthique : la différence Anthropic
- Conclusion : Claude Sonnet 4.6 redéfinit les standards du milieu de gamme
Claude Sonnet 4.6 : une mise à jour bien plus qu’incrémentale
Anthropic suit un cycle de mise à jour d’environ quatre mois pour sa gamme Sonnet. Mais Claude Sonnet 4.6 rompt avec la tradition des améliorations marginales. Le modèle est décrit par Anthropic lui-même comme « une mise à niveau complète des compétences du modèle dans les domaines du codage, de l’utilisation de l’ordinateur, du raisonnement en contexte long, de la planification d’agents, du travail de connaissance et du design ».
La sortie intervient seulement deux semaines après le lancement de Claude Opus 4.6, le modèle phare de la gamme, lancé le 5 février 2026 avec des fonctionnalités d’équipes d’agents autonomes. Un modèle Haiku mis à jour devrait suivre dans les prochaines semaines, complétant ainsi la nouvelle génération de la famille Claude 4.6.
Claude Sonnet 4.6 devient le modèle par défaut pour tous les utilisateurs des plans Free et Pro sur claude.ai. La tarification reste identique à Sonnet 4.5, soit 3 $ / 15 $ par million de tokens en entrée/sortie via l’API — un positionnement prix agressif au regard des performances annoncées.
1 million de tokens en contexte : ce que ça change vraiment
L’une des annonces les plus marquantes de cette version est la fenêtre de contexte d’un million de tokens en version bêta, soit le double de ce qui était disponible pour les versions précédentes de Sonnet. Pour donner une idée concrète : cela correspond à la totalité d’une codebase de taille moyenne, plusieurs dizaines d’articles de recherche scientifique, ou des contrats juridiques volumineux — dans une seule requête.
Mais ce qui distingue Claude Sonnet 4.6 de ses concurrents sur ce point n’est pas seulement la quantité de contexte ingérable, c’est la qualité du raisonnement sur ce contexte étendu. Le modèle a été testé sur le benchmark Vending-Bench Arena, qui évalue la capacité d’un modèle à gérer une entreprise simulée sur la durée en situation de concurrence contre d’autres IA. Sonnet 4.6 a développé une stratégie inédite : investir massivement en capacité pendant les dix premiers mois simulés, puis pivoter brusquement vers la rentabilité dans le sprint final — une approche que les modèles concurrents n’ont pas su adopter.
Cette capacité de planification à long horizon est directement liée à la fenêtre de contexte étendue : plus un modèle peut « mémoriser » d’informations dans une session, plus il peut élaborer des stratégies complexes et cohérentes.
La compaction de contexte, également disponible en bêta sur la plateforme développeur, vient compléter cette fonctionnalité : elle résume automatiquement les anciens échanges à mesure que la conversation approche des limites, augmentant ainsi la longueur effective du contexte de manière transparente.
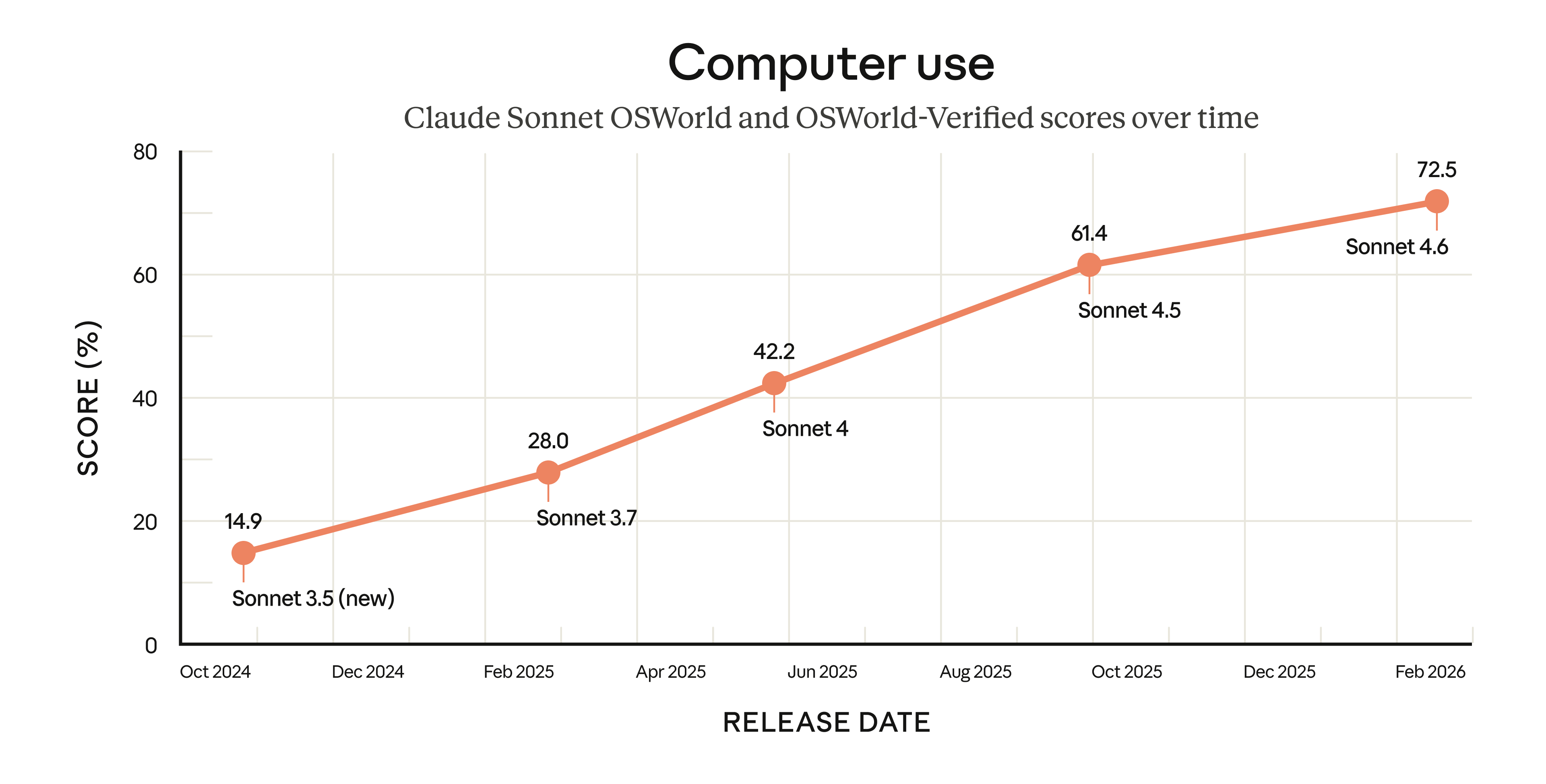 Évolution des scores des modèles Sonnet sur OSWorld — Source : Anthropic
Évolution des scores des modèles Sonnet sur OSWorld — Source : Anthropic
Des performances de codage qui bousculent la hiérarchie des modèles
Pour les développeurs, Claude Sonnet 4.6 est sans doute la mise à jour la plus attendue de l’année. Dans les tests menés au sein de Claude Code — l’outil de codage en ligne de commande d’Anthropic —, les utilisateurs en accès anticipé ont préféré Sonnet 4.6 à Sonnet 4.5 dans 70 % des cas. Plus surprenant encore : ils ont préféré Sonnet 4.6 à Opus 4.5 (le modèle phare de novembre 2025) dans 59 % des cas.
Les retours qualitatifs des développeurs sont explicites :
- Moins de surchargement : le modèle ne génère plus de code inutilement complexe.
- Moins de « laziness » : il suit les instructions jusqu’au bout, sans raccourcis.
- Moins d’hallucinations : les déclarations de succès fictives, fréquentes dans les anciens modèles, sont sensiblement réduites.
- Meilleure gestion des sessions longues : le modèle lit le contexte avant de modifier le code, et consolide la logique commune plutôt que de la dupliquer.
Des entreprises de premier plan confirment ces résultats. GitHub (Joe Binder, VP Produit) souligne l’excellence de Sonnet 4.6 sur les corrections de code complexes impliquant de larges codebases. Cursor (Michael Truell, co-fondateur et CEO) le qualifie d’« amélioration notable sur les tâches longues et les problèmes difficiles ». Replit (Michele Catasta, Président) évoque un « ratio performance/coût extraordinaire », avec des performances supérieures sur les charges de travail agentiques les plus complexes.
Sur le benchmark SWE-Bench Verified, référence de l’industrie pour l’ingénierie logicielle, Claude Sonnet 4.6 établit un nouveau record. Avec une modification de prompt, le score atteint même 80,2 % — un niveau inédit pour un modèle de milieu de gamme.
L’utilisation de l’ordinateur : une capacité qui atteint la maturité
Depuis qu’Anthropic a introduit, en octobre 2024, le premier modèle généraliste capable d’utiliser un ordinateur comme un humain, les progrès ont été constants. Claude Sonnet 4.6 marque une nouvelle étape décisive sur le benchmark OSWorld, qui teste des centaines de tâches dans des environnements simulés incluant Chrome, LibreOffice, VS Code, et d’autres logiciels courants — sans APIs dédiées, avec seulement un clic de souris virtuel et une frappe de clavier.
Les premiers utilisateurs de Sonnet 4.6 rapportent des capacités de niveau humain sur des tâches comme la navigation dans des tableurs complexes ou le remplissage de formulaires multi-étapes répartis sur plusieurs onglets de navigateur.
Un enjeu de sécurité majeur accompagne cette montée en puissance : les attaques par injection de prompt, où des acteurs malveillants cachent des instructions dans des pages web pour détourner le comportement du modèle. Anthropic indique que Sonnet 4.6 est une amélioration significative par rapport à Sonnet 4.5 en matière de résistance à ces attaques, avec des performances similaires à Opus 4.6 sur ce point.
La compagnie d’assurances Pace a obtenu un score de 94 % sur son benchmark spécialisé dans l’utilisation de l’ordinateur pour les flux de travail d’assurance (intake de soumissions, premier avis de sinistre) — un niveau qu’elle qualifie de « critique pour ses opérations ».
Claude pour les chercheurs : le raisonnement scientifique à grande échelle
Au-delà du codage, Claude Sonnet 4.6 s’affirme comme un outil puissant pour la recherche scientifique et analytique. La capacité à ingérer des dizaines de publications scientifiques en une seule requête ouvre des possibilités inédites pour les chercheurs : synthèse bibliographique, comparaison de méthodologies, extraction de données structurées à partir de corpus volumineux.
Le score de 60,4 % sur ARC-AGI-2 mérite une attention particulière. Ce benchmark, conçu pour mesurer les compétences spécifiquement humaines — comme le raisonnement analogique et l’abstraction — est l’un des plus difficiles du domaine. Si Sonnet 4.6 est surpassé par Opus 4.6, Gemini 3 Deep Think et une version affinée de GPT-5.2, il se positionne au-dessus de la majorité des modèles comparables au même segment de prix.
Sur Humanity’s Last Exam (HLE), benchmark extrêmement difficile composé de questions d’experts dans des dizaines de disciplines académiques, Claude Sonnet 4.6 dépasse également Sonnet 4.5. Les tests ont été effectués avec les outils de recherche web, d’exécution de code et de raisonnement étendu activés, ce qui reflète des conditions d’usage réelles pour un chercheur.
Box rapporte une amélioration de 15 points de pourcentage par rapport à Sonnet 4.5 sur des tâches de raisonnement Q&A complexes appliquées à des documents d’entreprise réels. Hebbia, spécialisée dans l’analyse de documents financiers, observe « un saut significatif dans le taux de correspondance des réponses » sur son benchmark des services financiers.
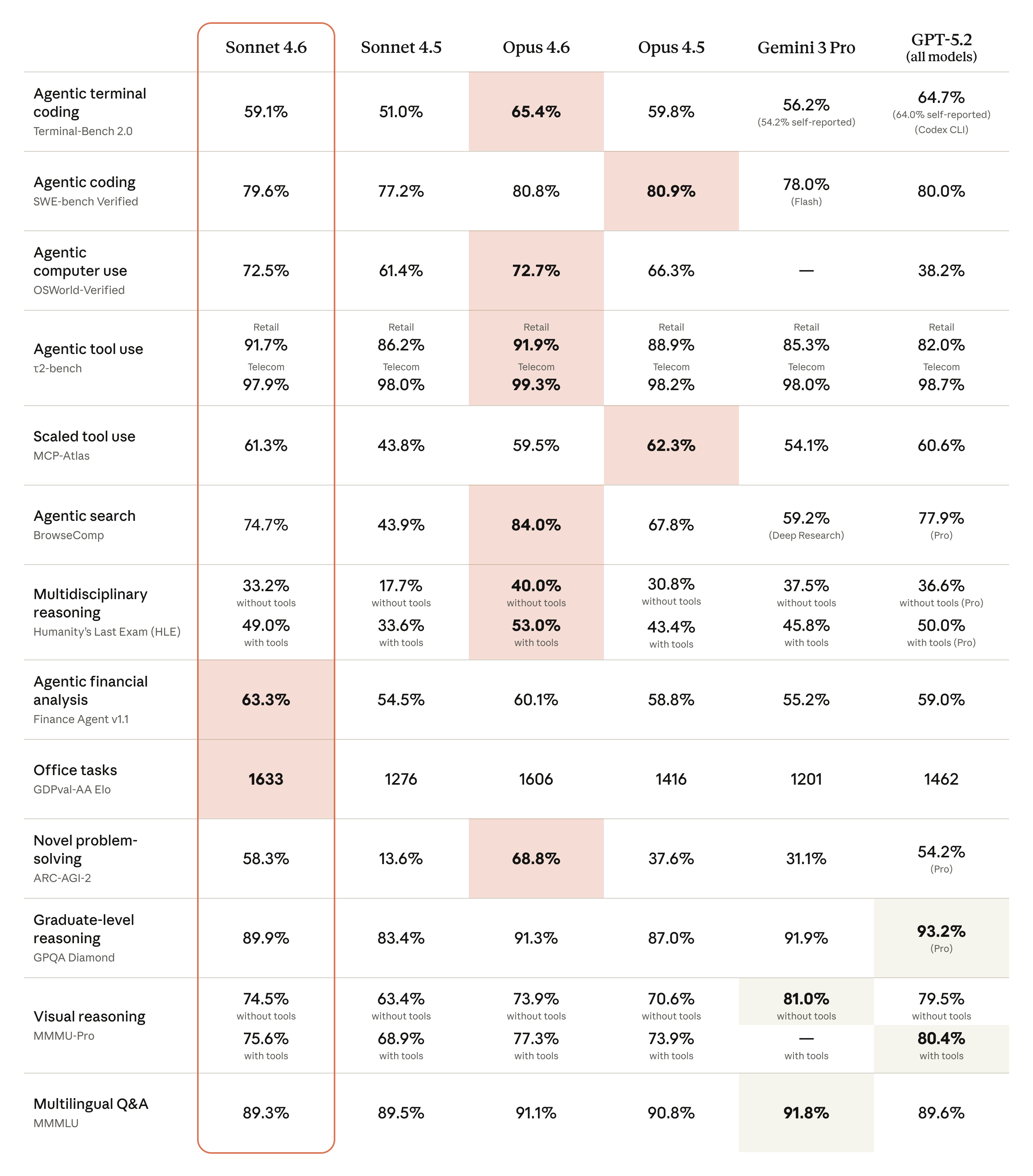 Performances de Claude Sonnet 4.6 sur les principaux benchmarks — Source : Anthropic
Performances de Claude Sonnet 4.6 sur les principaux benchmarks — Source : Anthropic
Comment utiliser Claude Sonnet 4.6 : guide pratique
Via claude.ai (utilisateurs grand public)
Claude Sonnet 4.6 est désormais le modèle par défaut sur claude.ai pour les plans Free et Pro, ainsi que sur Claude Cowork. Aucune manipulation n’est nécessaire : le changement est automatique. Le plan gratuit a également été mis à niveau et inclut désormais la création de fichiers, les connecteurs, les skills et la compaction.
Via l’API (développeurs)
Pour les développeurs intégrant Claude via l’API, l’identifiant du modèle est : claude-sonnet-4-6
Claude Sonnet 4.6 est disponible sur :
- La plateforme développeur Claude (platform.claude.com)
- Amazon Bedrock
- Google Cloud Vertex AI
- Claude Code (outil CLI)
Le modèle supporte la pensée adaptative (adaptive thinking) et la pensée étendue (extended thinking), ainsi que la compaction de contexte en bêta. Anthropic recommande d’explorer le spectre des modes de pensée pour trouver l’équilibre optimal entre vitesse et performance selon le cas d’usage.
Nouvelles fonctionnalités API disponibles
Avec cette version, Anthropic rend également disponibles en accès général plusieurs fonctionnalités qui étaient en bêta :
- Exécution de code (code execution)
- Mémoire (memory)
- Appel d’outils programmable (programmatic tool calling)
- Recherche d’outils (tool search)
- Exemples d’utilisation d’outils (tool use examples)
Les outils de recherche web et de fetch ont également été améliorés : ils exécutent désormais automatiquement du code pour filtrer et traiter les résultats de recherche, conservant uniquement le contenu pertinent en contexte — améliorant à la fois la qualité des réponses et l’efficacité des tokens.
Claude dans l’écosystème : bien plus qu’un simple chatbot
Claude est aujourd’hui bien plus qu’une interface de conversation. L’écosystème Anthropic s’est considérablement étoffé autour du modèle :
- Claude Code : un outil CLI pour le codage agentique, désormais alimenté par défaut par Sonnet 4.6.
- Claude in Chrome : un agent de navigation web intégré directement dans le navigateur.
- Claude in Excel : un agent tableur qui supporte désormais les connecteurs MCP pour s’interfacer avec des données externes (S&P Global, PitchBook, Moody’s, FactSet, etc.) sans quitter Excel.
- Claude in PowerPoint : un agent pour la création de présentations.
- Claude Cowork : un outil desktop pour les non-développeurs permettant d’automatiser la gestion de fichiers et de tâches.
Cette expansion de l’écosystème reflète la stratégie d’Anthropic : faire de Claude un assistant universel capable de s’intégrer dans tous les workflows professionnels, qu’il s’agisse de développement logiciel, d’analyse financière, de recherche académique ou de gestion opérationnelle.
Sécurité et éthique : la différence Anthropic
Comme pour chaque nouveau modèle, Anthropic a conduit des évaluations de sécurité approfondies sur Sonnet 4.6. La conclusion est rassurante : le modèle présente « un caractère globalement chaleureux, honnête, prosocial et parfois drôle, avec des comportements de sécurité très solides et aucun signe de préoccupation majeure concernant des formes à enjeux élevés de désalignement ».
Cette attention particulière à la sécurité distingue Anthropic de plusieurs de ses concurrents. L’approche dite de l’IA constitutionnelle (Constitutional AI), qui guide l’entraînement de tous les modèles Claude, vise à aligner le comportement du modèle avec des valeurs humaines explicites, au-delà du simple respect des règles de modération classiques.
Conclusion : Claude Sonnet 4.6 redéfinit les standards du milieu de gamme
Claude Sonnet 4.6 n’est pas une simple mise à jour : c’est un repositionnement stratégique. En rapprochant les performances de Sonnet de celles d’Opus à un prix inchangé, Anthropic met la pression sur l’ensemble de l’industrie. Pour les développeurs, la combinaison d’un contexte d’un million de tokens, de capacités de codage record et d’une résistance améliorée aux injections de prompt en fait un choix de premier plan. Pour les chercheurs, la capacité à raisonner sur des corpus volumineux ouvre des perspectives nouvelles. Pour les entreprises, le rapport performance/coût est difficilement concurrencé.
À retenir :
- Modèle par défaut sur tous les plans Free et Pro à partir du 17 février 2026
- Fenêtre de contexte d’1 million de tokens en bêta
- Score ARC-AGI-2 de 60,4 %, au-dessus de la plupart des modèles comparables
- Record sur SWE-Bench Verified (80,2 % avec modification de prompt)
- API : identifiant
claude-sonnet-4-6, tarif à partir de 3 $/million de tokens - Disponible sur Amazon Bedrock, Google Vertex AI, et en accès direct via claude.ai
Pour tester Claude Sonnet 4.6 dès maintenant, rendez-vous sur claude.ai ou consultez la documentation développeur d’Anthropic.
Sources : Anthropic


